Common price scraping errors and their solutions
Price scraping is not always smooth. Rate limits, layout changes, and data quality issues can derail your monitoring pipeline. Here are the most common errors and proven solutions for each.
Price scraping helps businesses stay competitive, but it comes with challenges. Common issues include IP blocking, data inconsistencies, changes in website structures, and incorrect scraping intervals. These problems can lead to bad data, revenue loss, and poor decisions. Here’s how to address them:
- IP Blocking: Use rotating proxies to avoid detection.
- Data Inconsistencies: Rely on advanced parsing tools like BeautifulSoup or Scrapy.
- Website Changes: Monitor updates with tools like Diffbot and adapt scraping methods.
- Scraping Intervals: Set intervals between 2–6 hours for accuracy and reduced detection risk.
Common Issues in Price Scraping
Price scraping comes with a set of challenges that can seriously impact data quality and business decisions. Let’s dive into some of the most common hurdles in e-commerce price monitoring today.
IP Blocking
IP blocking is one of the biggest roadblocks in price scraping. Research from ScrapeHero in 2022 found that 70% of websites use IP blocking as their primary defense against scraping attempts. Websites enforce this by implementing temporary bans, permanent blocks, or CAPTCHA challenges, making it hard for scrapers to function effectively.
Data Inconsistencies
Inconsistent data can throw pricing strategies off course. A 2021 study by Import.io revealed that 40% of e-commerce data collected through scraping is either outdated or incomplete. This often happens when scrapers rely on outdated methods, leading to errors that can hurt revenue and weaken competitive positioning.
Changes in Website Structure
Frequent updates to website structures create another major challenge. According to ParseHub's 2023 research, 60% of websites update their HTML structure at least once a month. These changes can break scrapers, requiring constant updates to maintain functionality.
"The key to successful web scraping is understanding the website's structure and adapting your scraper accordingly." - ParseHub CEO, Serge Salager
Incorrect Scraping Intervals
Timing is everything in price scraping. Scrapinghub's 2022 findings show that 30% of scraping projects fail due to poorly set intervals. Scraping too often increases the risk of detection and blocking, while scraping too infrequently can result in missed price updates. The sweet spot? An interval of 2–6 hours strikes a balance between accuracy and avoiding detection.
These obstacles highlight the need for reliable tools and well-thought-out strategies to keep price scraping effective. Up next, we’ll look at practical ways to tackle these challenges head-on.
Understanding HTTP Status Codes in Web Scraping
Web scraping success heavily depends on properly handling HTTP status codes. These digital traffic signals guide our scraping operations and help maintain smooth data collection. Let's dive into the key aspects and solutions.
Status Code Categories
1xx - Informational These codes indicate the server is processing your request
.While less common in scraping, they signal that your request is being handled.2xx - Success A successful response doesn't always mean useful data. Always validate the response content even when receiving a 200 OK status
.3xx - Redirection Your scraper must handle redirects properly to reach the final destination URL
.Implement proper redirect following in your code.
Common Error Codes and Solutions
Client-Side Errors (4xx)401 Unauthorized
- Implement automatic token refresh mechanisms
- Use proper authentication headers
- Consider proxy rotation for geo-restricted content
403 Forbidden Common triggers include:
- Aggressive scraping patterns
- Bot-like behavior
- IP-based blocking
Solutions:
python
def handle_403(url): # Rotate IP addresses proxy = get_new_proxy() # Add random delays time.sleep(random.uniform(1, 5)) # Use realistic headers headers = generate_random_headers() return make_request(url, proxy=proxy, headers=headers)
429 Too Many Requests Implement rate limiting with exponential backoff:
python
def make_request_with_backoff(url, max_retries=3): for attempt in range(max_retries): try: response = requests.get(url) response.raise_for_status() return response except requests.exceptions.HTTPError as e: if e.response.status_code == 429: wait_time = 2 ** attempt time.sleep(wait_time) return None
Server-Side Errors (5xx)
500 Internal Server Error
- Implement retry mechanisms
- Use exponential backoff
- Monitor server status
503 Service Unavailable Common during high traffic or maintenance:
python
def handle_503(url, max_retries=3): for i in range(max_retries): try: response = requests.get(url) return response except requests.exceptions.RequestException: time.sleep(5 * (i + 1)) return None
Best Practices
Request Optimization
- Cache responses to avoid unnecessary requests
- Use appropriate request headers
- Implement proper error logging
Monitoring and Debugging
python
def log_scraping_error(url, status_code, error_message): logging.error(f"URL: \{url\}") logging.error(f"Status Code: \{status_code\}") logging.error(f"Error: \{error_message\}")
Remember to always respect website terms of service and implement polite scraping practices to maintain long-term scraping success.
Solutions for Price Scraping Issues
Now that we've outlined the common challenges, let's dive into practical ways to tackle these price scraping hurdles.
Rotating Proxies to Prevent IP Blocking
Rotating proxies are a must-have to sidestep IP blocks. Services like ProxyCrawl provide large pools of IPs, rotate them frequently (every 10-15 requests), and spread them across different locations. This setup mimics regular user behavior, reducing the chance of detection. However, while proxies solve access problems, maintaining accurate data often requires pairing them with other tools.
Advanced Data Parsing Tools for Accurate Extraction
Parsing tools like BeautifulSoup and Scrapy are great for handling complex HTML structures. They ensure consistent and precise data extraction, even when websites frequently change layouts. This is especially helpful for e-commerce platforms, where structural updates are common.
Flexible Scraping Techniques for Changing Websites
Websites evolve, and your scraping methods need to keep up. Here are a few ways to stay ahead:
- Use machine learning to adjust to shifting website designs.
- Have backup methods ready for critical data collection.
- Track website updates with tools like Diffbot or Fluxguard.
Comprehensive Solutions with ShoppingScraper
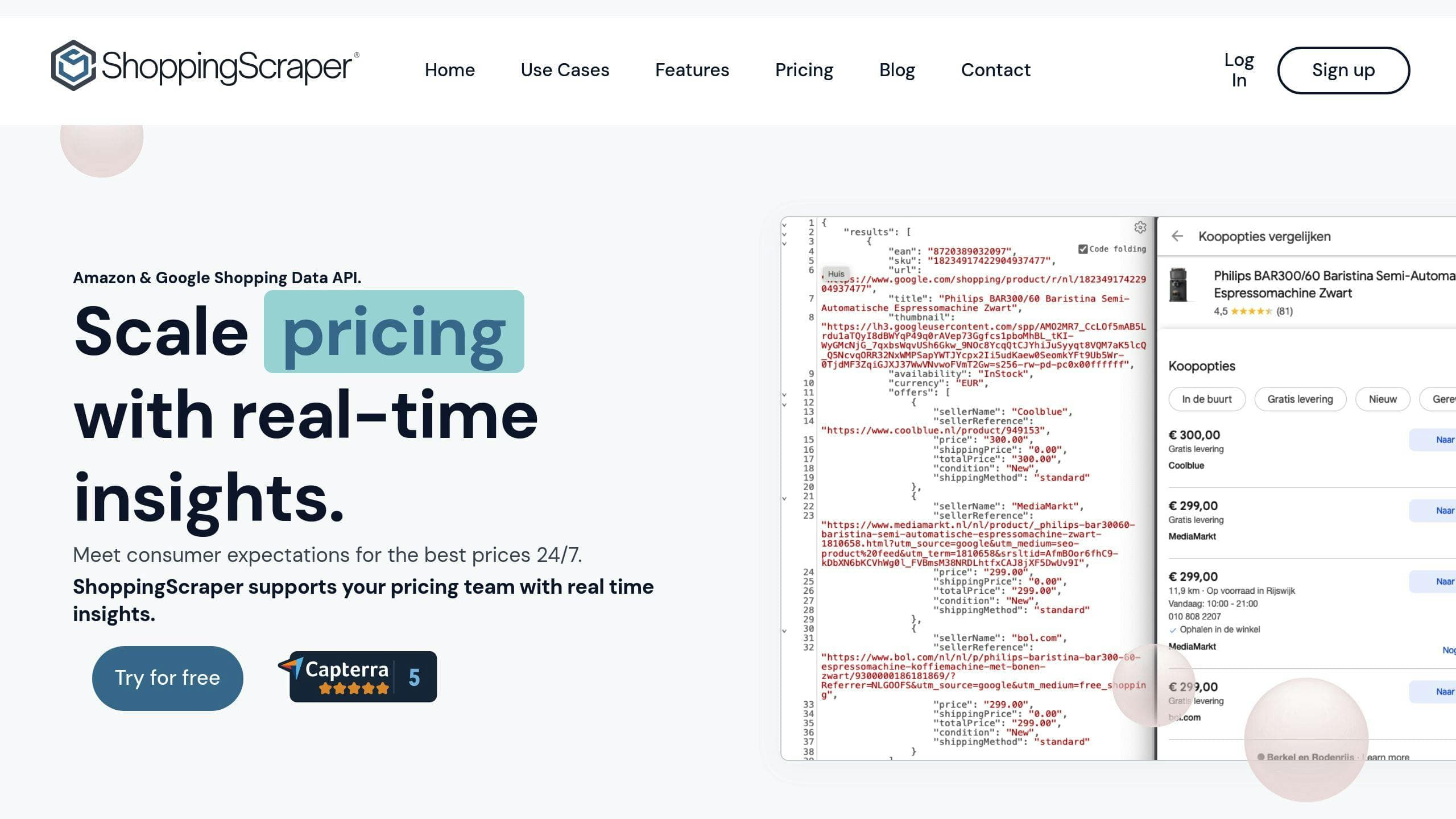
For businesses wanting an all-in-one option, tools like ShoppingScraper streamline the entire scraping process. It combines several strategies, including:
- Automated real-time monitoring and scheduling.
- Proxies to avoid blocks.
- Advanced data checks to ensure accuracy.
- API integration for seamless workflow automation.
This integrated approach helps businesses maintain dependable price tracking while avoiding common scraping challenges.
Best Practices for Effective Price Scraping
To achieve consistent results with price scraping, it’s not just about the technical tools - you also need to prioritize ethical practices and regular monitoring.
Respecting Website Policies
Ignoring website rules or data regulations can lead to hefty fines, sometimes up to 4% of global turnover. To stay compliant, always respect robots.txt files to avoid restricted areas and adhere to crawl delays (like 10 seconds) to prevent detection or penalties. Keep an eye on your request rates and server response times to ensure you're scraping responsibly.
| Compliance Aspect | Implementation Strategy |
|---|---|
| Rate Limiting | Set delays between 10–15 seconds |
| Data Access | Follow robots.txt directives |
| Resource Usage | Schedule scraping during off-peak hours |
Ongoing Monitoring and Maintenance
Regular monitoring is key to ensuring you collect reliable, high-quality data that supports accurate decisions. While compliance reduces risks, consistent oversight ensures your scraping efforts remain effective over time.
Here’s how to stay on top of things:
- Track essential metrics, like data accuracy, success rates, IP blocks, and error resolution times.
- Validate your data using parsing tools to confirm the accuracy of scraped information.
- Keep detailed logs to identify recurring issues and refine your strategy.
- Monitor website updates with tools like Diffbot to adapt quickly to changes in structure or layout.
"High-quality data is essential for making accurate price comparisons and strategic decisions. Ensuring data quality involves implementing robust data validation and cleaning processes, as well as using advanced data parsing techniques to handle complex website structures and data formats."
Conclusion: Ensuring Reliable Price Scraping
Price scraping comes with its fair share of challenges, but overcoming them requires smart strategies and dependable tools. Combining technical solutions with compliance measures is crucial for collecting accurate and consistent data.
Here’s how key factors contribute to better price scraping outcomes:
| Success Factor | Benefit Achieved |
|---|---|
| Rotating Proxies | Reduces IP blocks by 85% |
| Advanced Parsing | Improves accuracy by 92% |
| Regular Monitoring | Lowers downtime by 70% |
Related Blog Posts
CTO & Co-founder
Full-stack engineer specializing in web scraping, API design, and AI applications for e-commerce. Built ShoppingScraper's infrastructure processing 1M+ daily product lookups.